Hashovací tabulka
- Zobecnění pole:
- Rozdíl je ve způsobu adresování.
- Místo množiny klíčů , které jsou vlastně indexy do pole, máme obecnou množinu klíčů .
- Hlavní idea: Hashovací funkce pro přepočet obecného klíče na index v tabulce.
Úvod do hashovacích tabulek
Implementace
struct table
data:[]key //pole klíčů
hash-function //hashovací funkceKostra přístupu k místu, kde je v tabulce klíč
- Počítáme index:
- Přistoupíme k prvku:
Kolize
- Pro množinu klíčů , velikost tabulky a hashovací funkci kolize nastane pokud: existují klíče tak že ale .
- Kolize určitě nastane, pokud : to plyne z Dirichletova principu
- I když máme může být pravděpodobnost, že dojde ke kolizi, vysoká (narozeninový paradox)
Řešení kolizí pomocí řetězení (chaining)
- Klíče, které se zahashují na stejný index ukládáme do seznamu
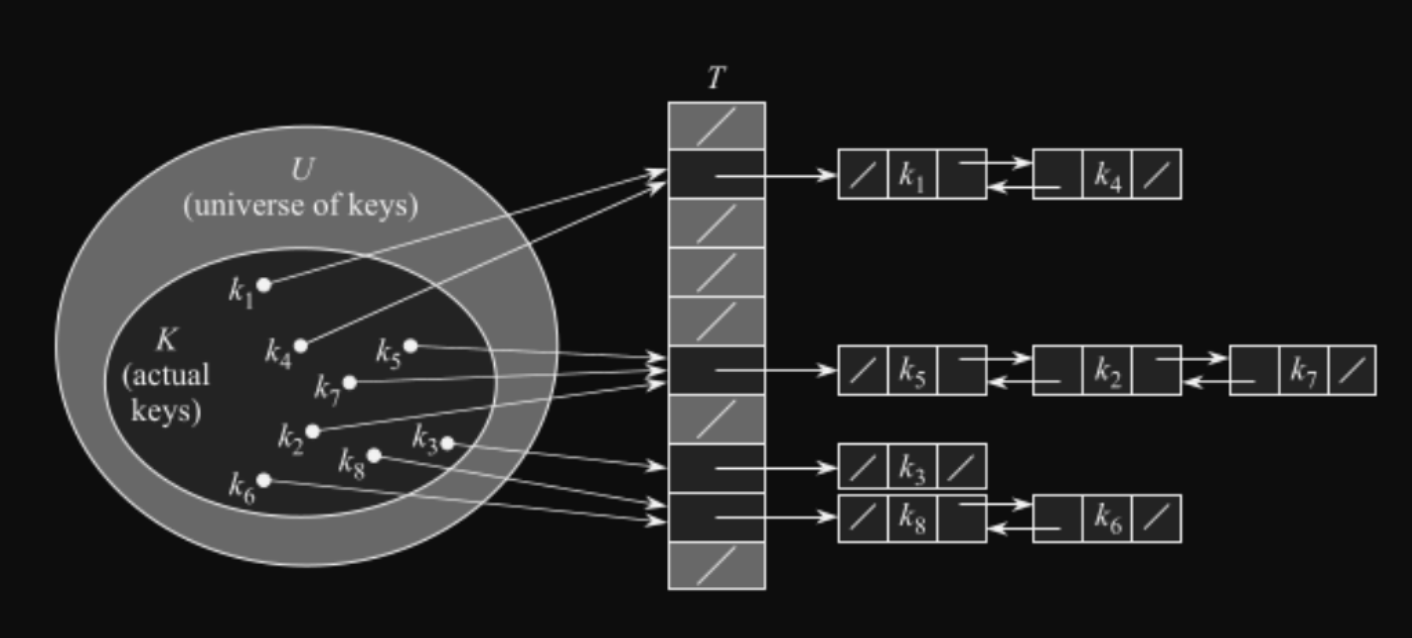
Implementace
struct table
data:[]list
hash-function//Argumenty T = table, k = key
proc insert(T,k)
index = h(k)
list-insert(T[index], x)proc delete(T, k)
index = h(k)
list-delete(T[index], x)proc search(T,k)
index = h(k)
list-search(T[index], k)Složitost v nejhorším čase
- Složitost
insertadeletezůstávají konstantní. - Složitost
searchmůže být v nejhorším případě lineární- všechny klíče prvků v tabulce zobrazili pomocí na stejnou hodnotu, nebo se klíč v tabulce nenachází
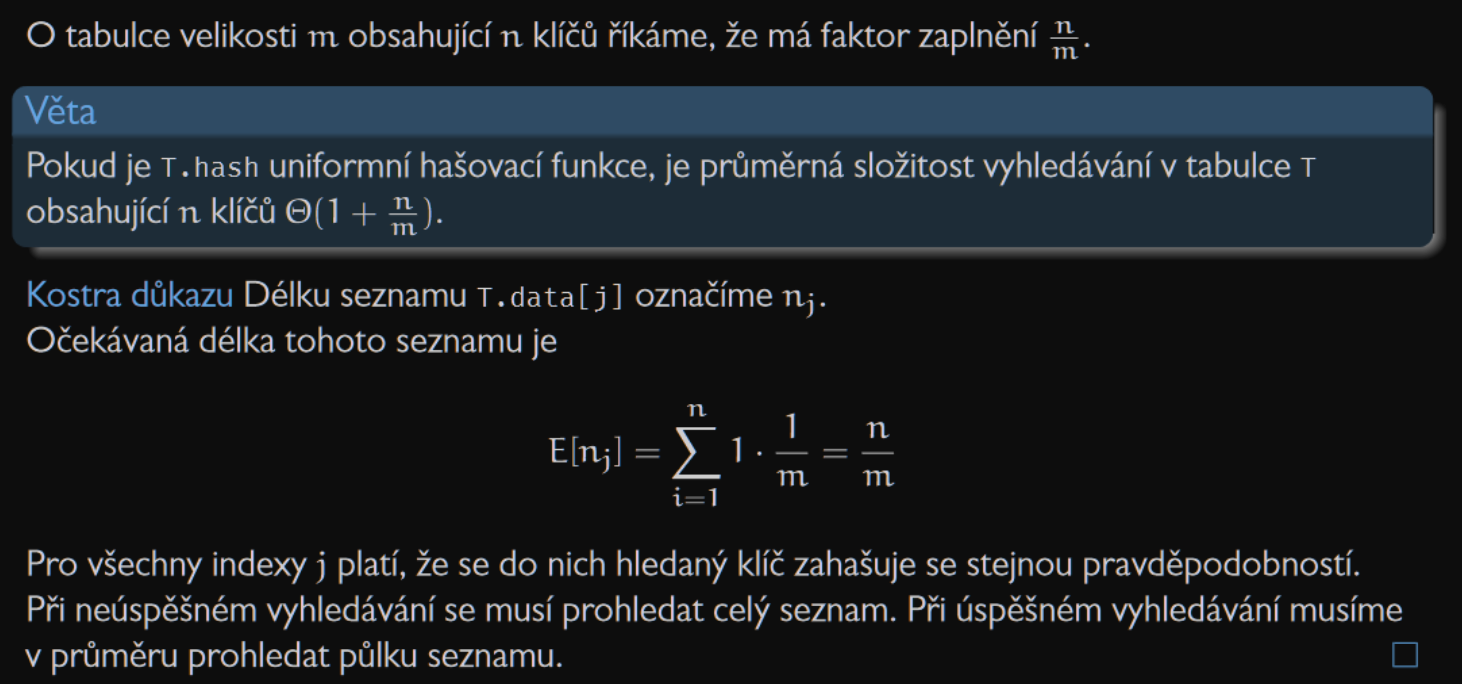
Složitost search v průměrném případě
Konstrukce hashovací funkce
-
Cíl je jednoduché rovnoměrné hashování
-
Potřebujeme znalost rozložení pravděpodobnosti při výběru klíče a nezávislost (= výběr jednoho klíče nezmění pravděpodobnosti výběru dalších klíčů)
-
Nejlepší co můžeme udělat je, aby hashovací funkce moc nezávisela na vzorech, vyskytujících se v datech.
-
Používáme heuristiky, jejichž cílem je, aby výsledek funkce závisel na všech částech klíče
-
Příklad závislosti na vzoru v datech:
- Klíče jsou celá čísla,
- Problém je, že výsledek závisí pouze na jednom bitu klíče.
- Aby funkce dobře fungovala, musíme předpokládat, že je stejně pravděpodobné, že klíč bude lichý jako že klíč bude sudý
- Klíče jsou celá čísla,
Obecný postup konstrukce
- Klíč bereme jako posloupnost číslic v nějaké číselné soustavě
- např. jako posloupnost bajtů = číslic v soustavě o základu
- Hashovací funkce má obvykle fáze:
- sekvenci čísel použijeme pro výpočet hodnoty, která ovšem může být větší než
- hodnotu z předchozího bodu upravíme tak, aby byla mezi a
Příklad

Tip
U dělící metody není dobré, když je velikost tabulky mocnina , protože pak výsledek záleží pouze na hodnotě spodních bitů (jejich počet odpovídá exponentu)
Metoda řešení kolize: Otevřené adresování
-
Prvky jsou v samostatné tabulce (neobsahuje seznamy prvků), prázdná políčka jsou
nil -
Velikost tabulky omezuje počet prvků, které se do tabulky vejdou (faktor zaplnění tabulky není nikdy větší než )
-
Pro účel vyhledávání a vkládání používáme průzkumné posloupnosti.
-
Vytvoříme průzkumnou funkci:
-
Platí pro ni, že
-
Průzkumná posloupnost pro klíč je potom
Princip otevřeného adresování
- Při vyhledávání indexu odpovídajícího klíči prohledáváme tabulku v pořadí odpovídající průzkumné posloupnosti pro .
- Pokud je na aktuálním indexu klíč různý od , pokračujeme v průzkumné posloupnosti dál.
- Pokud je na aktuálním indexu
nil, klíč se v tabulce nenachází. - Pokud projdeme celou průzkumnou posloupnost, klíč se v tabulce nenachází.
- Analogický postup použijeme pro přidávání uzlu: uzel přidáme na první index z průzkumné posloupnosti, na kterém je
nil. - Odstranění prvku z tabulky by způsobilo přerušení průzkumné posloupnosti při vyhledávání. Prvky v tabulce proto musíme ponechat, ale dát jim příznak, že jsou smazány. Potom musíme příslušným způsobem upravit procedury pro přidávání (přidáváme i na místo, kde je smazaný prvek) a prohledávání (smazané prvky přeskakujeme).
- Složitost těchto operací pak ale nezávisí přímo na faktoru zaplnění tabulky. Pokud potřebujeme i operaci mazání, je lepší použít řetězení.
Lineární prozkoumávání
-
Máme hashovací funkci . K ní vytvoříme průzkumnou funkci
-
Průzkumná posloupnost tedy začíná a pak lineárně projdeme zbytek políček tabulky stejně, jako bychom procházeli pole (s tím, že když se dostaneme na konec tabulky, začneme znovu od začátku)
-
Navštívím všechna políčka
-
Existuje různých průzkumných posloupností
-
Problém je primární shlukování: vzniknou dlouhé úseky obsazených políček, které tak zvyšují průměrný čas nutný k vyhledávání
Kvadratické prozkoumávání
-
Máme hashovací funkci . K ní vytvoříme průzkumnou funkci
- jsou vhodně zvolené konstanty
-
Pro některou kombinaci hodnot a nemusí být průzkumná funkce (máme takové, že (Je těžké trefit dokonalou kombinaci a )
-
Pokud je např. prvočíslo, pak většina voleb (např. nebo ). vede k tomu, že délka průzkumné posloupnosti před tím, než narazíme na opakující se hodnotu, je přibližně
-
Vzniká sekundární shlukování - pokud máme , ale , mají a stejné průzkumné sekvence.
-
Existuje různých průzkumných posloupností
Příklady průzkumných posloupností
- Předpokládejme, že .
Dvojité hashování
-
Pro hashovací funkce zavedeme průzkumnou funkci
-
Hashovací funkce určuje počáteční pozici, hashovací funkce určuje offset, o který se posouváme
-
Aby byla prohledávací funkce, musí být a nesoudělné. Můžeme zvolit:
- jako prvočíslo
-
Pro prvočíselné existuje průzkumných posloupností
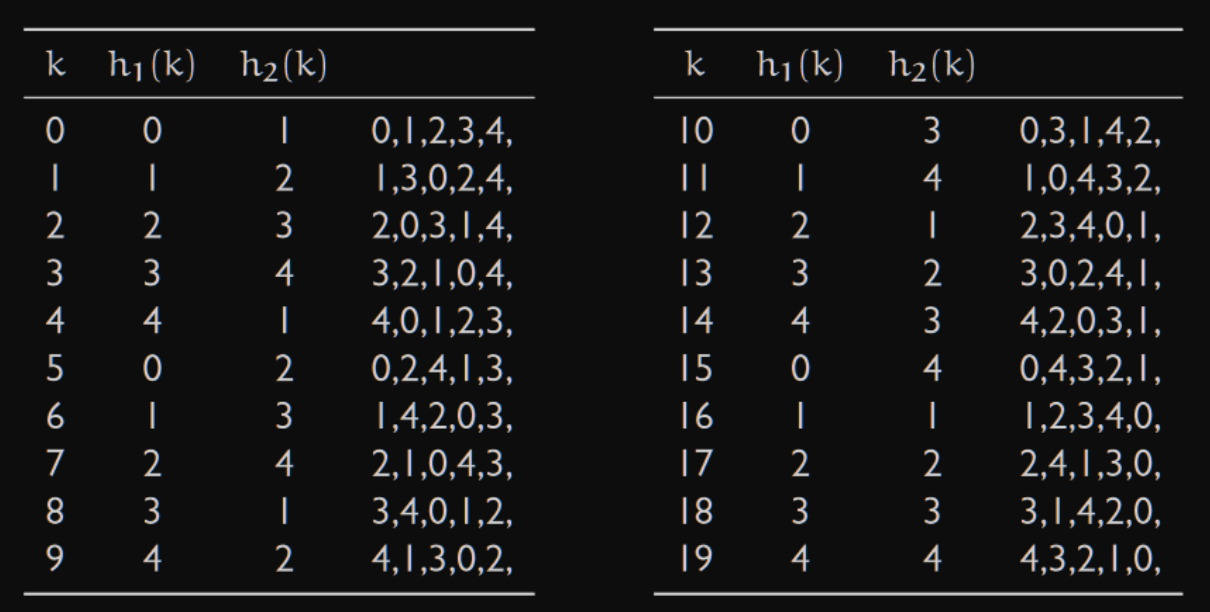
Příklad pro
m=5
Navigace
Předchozí: B stromy, operace a jejich složitost Následující: Základní grafové algoritmy - průchod do šířky, průchod do hloubky, topologické uspořádání Celý okruh: 1. Teoretické základy informačních technologií