Replikace
- Používá se k zajištění dostupnosti, spolehlivosti a odolnosti vůči selhání.
- Princip spočívá v tom, že určitá část dat nebo služeb je duplikována a tyto kopie jsou umístěny na více uzlech.
- Cílem replikace:
- minimalizovat dopady chyb,
- zvýšit dostupnost,
- zlepšit výkonnost DS.
- Např. Cache-ování, CDN (Content Deliver Network), DNS, …
Konzistence
- Problém konzistence je spojen s akcí čtení z různých replik zároveň. Může se stát, že se dostaneme k rozdílným datům (zpoždění, cache, …)
- Typ konzistence nám říká, jaké data dostaneme při čtení z různých replik.
Typy konzistence
- Silná konzistence
- Při čtení z různých replik dostaneme vždy stejná data.
- Jako kdyby byly změny propagovány okamžitě.
- Kauzální konzistence
- Klade důraz na respektování kauzálních vztahů mezi operacemi.
- Pokud operace ovlivňuje operaci , pak je třeba zajistit, aby byla provedena dříve než ().
- Je slabší jak silná konzistence, ale silnější než sekvenční.

- Sekvenční konzistence
- Některé repliky mohou být pozadu, ale změny jsou stále ve stejném pořadí.
- To vyvolává však problém, že při sekvenční konzistenci klient může číst nejprve od uzlu, který je aktuální a následně od uzly, který je pozadu.
- Eventuální konzistence
- Připouští dočasnou nesrovnalost mezi replikami dat
- avšak zároveň zaručuje, že v konečném důsledku budou všechny repliky dosahovat konzistence.
- Typické cache-ování.
- Vhodné například pro počítání návštěvníků.
Replikace za pomocí Raft algoritmu
- Zahrnuje vytvoření replik a řízení jejich stavu a replikačních operací.
- Raft je algoritmus pro dosažení shody mezi uzly v systému ohledně stavu nebo hodnoty.
Postup:
- Zvolí se lídr.
- Klient zasílá požadavky na provedení operace lídrovi.
- Každý uzel udržuje svůj log (seznam operací, které mají být vykonány, …).
- Lídr třídí požadavky do svého logu a pošle tuto informaci ostatním uzlům.
- Pokud lídr obdrží potvrzení od většiny, provede operaci a pošle informaci ostatním uzlům. Ti poté provedou operaci.
- Logy jednotlivých uzlů nemusí být stejné. Musí řešit lídr:
- Kromě operace je zaslán index logu.
- Pokud je nějaký index přeskočen je ohlášeno lídrovi.
- Lídr udržuje informace o dalším indexu každého uzlu, pokud dojde k překročení, sníží index a pošle opět data (pokud je stále přeskočený, situace se opakuje).
Problém při volbě lídra
- Může být zvolen lídr s neaktuálním logem.
- Při volbě uzel hlasuje pro kandidáta pouze pokud je log kandidáta aktuálnější (nebo stejně aktuální) jak jeho vlastní.
- Aktuálnost je měřena volebním obdobím (pozdější vyhrává) a délkou logu (delší vyhrává)
- Lídr NIKDY nepřepisuje svůj log, pouze přidává.
Chain replikace
- Máme řetězec uzlů, první je head a poslední tail.
- Head obstarává zápis a tail čtení.
Postup:
- Head přijme požadavek a předá sousedovi (všechny uzly si ukládají zprávu do logu).
- Zpráva se dostane až k tail a poté její potvrzení cestuje zpátky k head (zpráva se provádí).
-
Je silně konzistentní.
-
Existuje samostatný (centrální) uzel dedikovaný na správu řetězce (jak se zachovat při výpadu, atd.) server
-
Může selhat až uzlů, při délce řetězce .
- Pokud selže head uzel je nahrazen svým následníkem.
- Pokud selže tail uzel je nahrazen svým předchůdcem.
- Pokud selže mezilehlý uzel propojení sousedních.
-
Problém, když selže centrální uzel (server), musíme jej také replikovat.
-
Zásadní rozdíl oproti replikací s volbou lídra:
- Všechny uzly mají k dispozici replikovaná data.
- Tail může poskytnout data pro čtení bez nutnosti kontaktovat ostatní uzly.
- Latence (jeden pomalý uzel zpomalí celý řetězec).
-
Možnost povolení čtení na mezilehlých uzlech oslabí silnou konzistenci na sekvenční.
- Mezilehlé uzly udržují více verzí dat (dirty a clean).
- Při propagaci k tail označeno dirty, při propagaci k head označeno jako clean.
- Při požadavku na čtení je poslána clean verze dat, nebo je kontaktován tail s dotazem na poslední potvrzenou verzi.
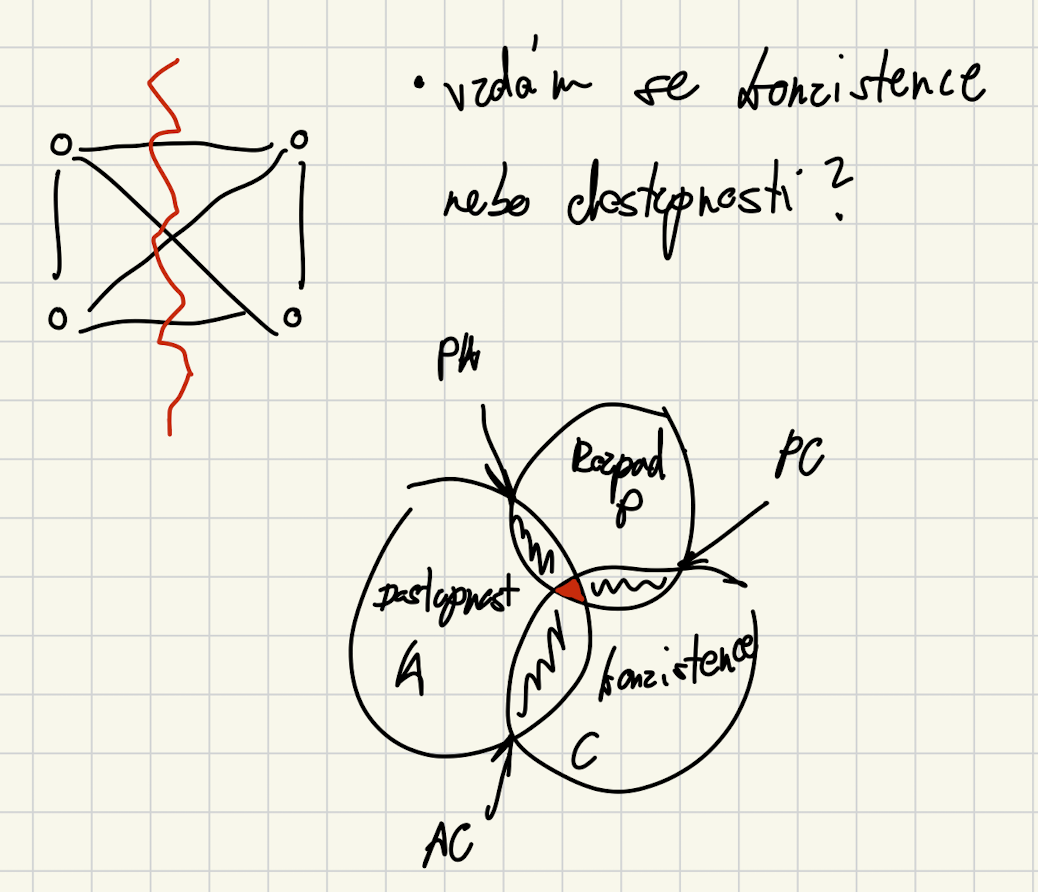
CAP a PACELC teorém
CAP teorém
- Síťovým problémům se nedá vyhnout.
- Když nastane rozpad (P) můžeme zachovat:
- dostupnost (Availability),
- konzistenci (Consistency).
- Nelze zachovat obojí.
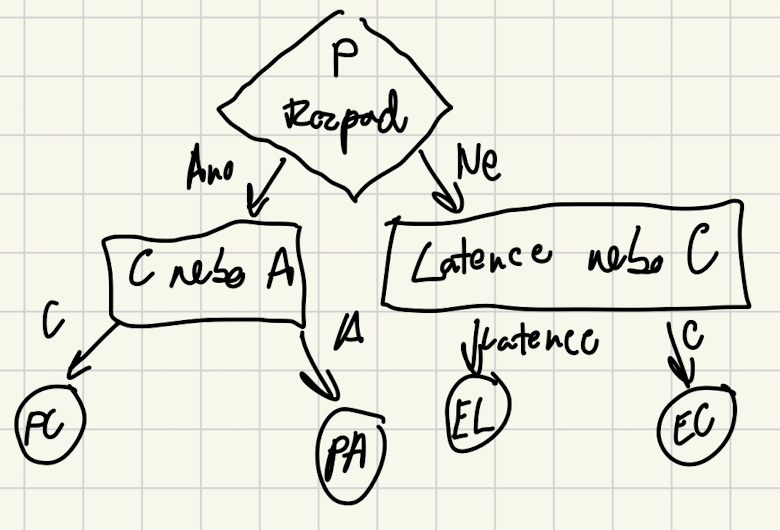
- Rozšířením CAP teorému získáme PACELC.
PACELC teorém
- Pokud (tolerance rozdělení na části), pak výběr mezi (dostupnost) a (konzistence), jinak (else) výběr mezi (latence) a (konzistence).
- Doplňuje CAP teorém tím, že zohledňuje nejen situaci, kdy dochází k výpadku sítě (partition tolerance), ale také situace bez výpadků, kdy musí být upřednostněna buď latence (Latency), nebo konzistence (Consistency)
CALM teorém
- Zaměřuje se na souvislost mezi konzistencí dat a monotonií logických formulí v DS.
- Tvrdí, že DS, který udržuje monotónní růst logických formulí, bude dosahovat nějaké formy konzistence bez nutnosti používat silně konzistentní mechanismy.
Monotonie
- Monotónní operace jsou takové, které nemění svůj výsledek v závislosti na počtu opakování nebo načítání (např. sjednocení).
- Pokud jsou operace monotónní, pak se jejich aplikací opakovaně nebo v různém pořadí nedojde k narušení konzistence dat.
*Navíc z hodin s panem doktorem Trnečkou.
Poznámky
- Shodu lze implementovat pomocí replikace.
- Shoda obecně vyžaduje broadcast/multicast protokol, který garantuje pořadí operací.
- Typy broadcast/multicast protokolů:
- Best-effort - uzel pošle zprávu všem ostatním, pokud neselže, jsou zprávy doručeny všem uzlům.
- Reliable - každý proces přeposílá obdrženou zprávu, když ji obdrží poprvbé, fungující uzly obdrží zprávu.
- Gossip - náhodné přeposílání.
Odbočka: Distribuce obsahu
- Obecně je potřeba popsat, jak vypadá aktualizace dat
- Pouze notifikace, že došlo ke změně
- Výhoda: menší zátěž
- Používá se pokud je mnoho update a málo read (může být proveden update několikrát bez čtení = zbytečné).
- Přenesení celých dat
- Nevýhoda: pomalé
- Výhodné pokud je často read)
- Operace, která má být vykonána
- Vyžaduje výpočetní výkon na replikách
- Pouze notifikace, že došlo ke změně
Odbočka: Protokoly
- Push
- Aktualizace je propagována k replikám, aniž by se ptali
- Vyžaduje evidenci replik
- Pull
- Aktualizace je propagována na dotaz klienta
- Může dojít k přetížení hlavní repliky
- Kompromis
- Push v pravidelných intervalech
- Pokud není proveden, klient provede pull
Odbočka: Detekce selhání
-
Řešíme dva body:
- Úplnost
- Přesnost
-
Úplnost
- Silná: Každý chybný uzel je detekován každým funkčním uzlem.
- Slabá: Každý chybný uzel je detekován alespoň jedním funkčním uzlem.
-
Přesnost
- Silná: Žádný funkční uzel není označen jako chybný
- Slabá: Alespoň jeden funkční uzel není označen jako chybný