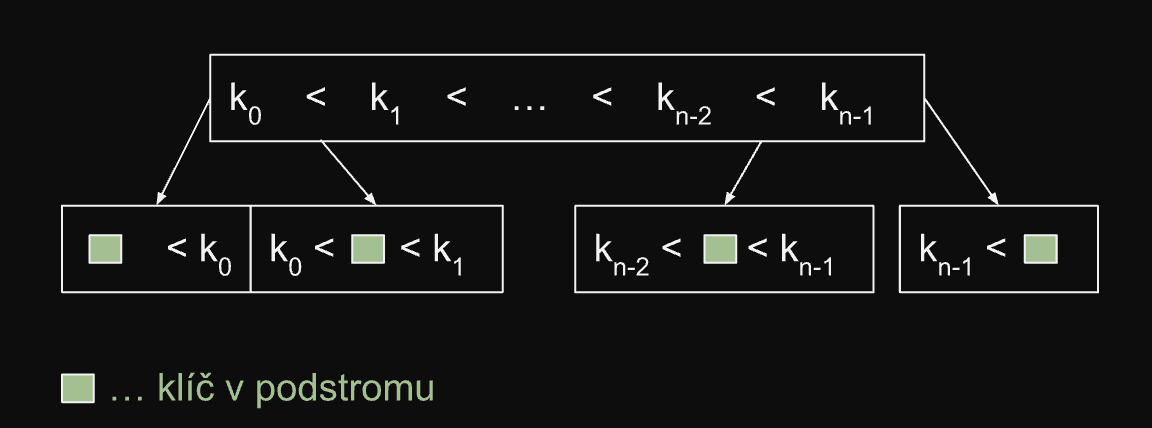
V uzlech může být uloženo více klíčů, maximálně však 2t−1. Ve všech uzlech mimo kořene však musí být uloženo minimálně t−1 klíčů(pokud je strom neprázdný je v kořeni vždy alespoň jeden klíč)
Pokud uzel obsahuje n klíčů, má 0 (je list) nebo n+1 potomků
Všechny listy ve stromu jsou ve stejné hloubce
Klíče jsou v uzlu uspořádány vzestupně
k0<k1<k2<...<kn−1 (1≤n≤2t−1)
Výška B-stromu: B strom s n≥1 klíči a t≥2 má výšku nejvýše logt2n+1
B-stromy jsou často používány v databázových systémech.
Zaměřují se na vlastnost snížení operací s diskem.
Úvod
Vlastnosti
Implementace
struct node { keys, // pole klicu o velikosti 2t-1 children, // pole pointeru na potomky o velikosti 2t parent, // pointer na rodiče n, // počet klíčů v uzlu leaf, // priznak toho, jestli je uzel listem data, // pointer na satelitni data …}
struct tree { root, // korenovy uzel}
proc create-empty-tree(T)//prázdný strom reprezentujeme pomocí kořenového uzlu, který neobsahuje žádný klíč x = new_node() x.leaf = true x.n = 0 T.root = x
Operace s B-stromy
Vyhledávání - O(tlogtn)
Zobecnění vyhledávání ve vyhledávacím stromě. Rozhodování, do kterého podstromu se vydáme je nyní založeno na porovnávání s polem klíčů, nikoliv jenom s jedním klíčem.
Neúspěsné vyhledávání končí v listu.
proc b-tree-search(x,k) i = 0 while i < x.n and k > x.keys[i] // kdyz cyklus skonci, bud i == x.n nebo k <= x.keys[i] i += 1 // cyklus skončil protoze k == x.keys[i] if i < x.n and k == x.keys[i] return x, i // nenašli jsme shodu s k a jsme v listu else if x.leaf return nil else b-tree-search(x.children[i], k)
Vyhledávání
Vložení prvku (dvoufázově) - O(tlogtn)
Uzel, kam budeme vkládat, nalezneme pomocí upravené operace b-tree-search, která vrací pointer na uzelx, a indexi v poli x.keys, na který budeme vkládat.
Vložení provedeme posunutím prvků v tomto poli od indexu idoprava a na uvolněné místo zapíšeme k.
Položku x.n zvětšíme o 1
Problém:
Uzel x je již zaplněný - x.n == 2t-1, vložením klíče do x bychom v tomto vrcholu měli 2t klíčů a porušili bychom podmínku z definice B-stromu.
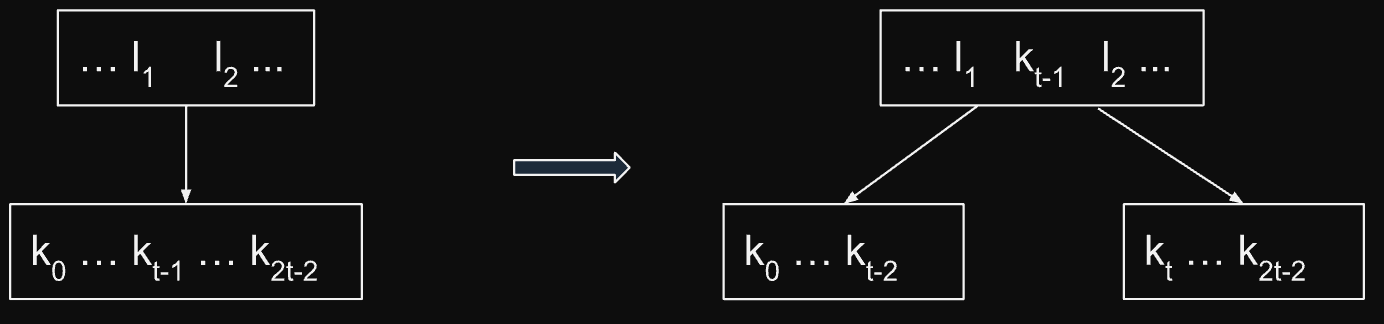
Rozdělením uzlu x na dva uzly, každý s t-1 klíči, a přesunem jednoho klíče do rodiče uzlu x.
Po rozdělení můžeme k vložit do příslušného uzlu.
Problém:
Rodič uzlu x ovšem může být před přidáním kt−1také zaplněn.
Před začleněním kt−1 jej tedy musíme také rozdělit.
Tím může vzniknout kaskáda dělení zaplněných uzlů, která může skončit až v kořeni.
Pokud je zaplněn kořen, rozdělíme jej a vytvoříme nový kořen, který bude obsahovat jenom jeden klíč.
Vložení prvku (jednofázově) - O(tlogtn)
Idea: Pokud v první fázi vkládání rozdělíme každý zaplněný uzel, na který narazíme (a to těsně před tím, než na něj během vyhledávání přejdeme), tak nikdy nenarazíme na problém přidávání do zaplněného uzlu.
Jsme-li během vyhledávání v uzlu x, který není zaplněn, a víme, že máme pokračovat s vyhledáváním do jeho potomka y, který je zaplněn, pak y rozdělíme ještě předtím, než na něj přejdeme. Protože x není zaplněn, můžeme klíč, který dělením y vznikne, vložit do x bez nutnosti tento uzel dělit. Tím zabráníme možné kaskádě dělení uzlů.
Pro vkládání máme dvě procedury: tree-insert, která bere jako argument strom a vypořádá se se situací, kdy je kořen zaplněný. Druhá procedura, tree-insert-nonfull již bere jako argument uzel: to je kořen podstromu, do kterého vkládáme. O něm předpokládáme, že není zaplněný
Ukázka vložení prvku (jednofázově)
proc split-child(x, i) // procedura rozdeli x.children[i] O(t) // 1. Vytvorime 2 uzly vnikle delenim z = new_node() y = x.children[i] z.leaf = y.leaf z.n = t - 1 y.n = t - 1 // 1.1 zkopirujeme pravou cast klicu a dat do z for j = 0; j < t-1; j = j + 1 z.keys[j] = y.keys[j + t] z.data[j] = y.data[j + t] // 1.2 zkopirujeme pravou cast pointeru na potomky do z if not y.leaf for j = 0; j < t; j = j + 1 z.children[j] = y.children[j + t] // 2. upravime x a zapojime do nej z a vlozime k_t // 2.1 posuneme klice a data v x o 1 doprava for j = x.n - 1; j >= i; j = j - 1 x.keys[j + 1] = x.keys[j] x.data[j + 1] = x.data[j] // 2.2 posuneme pointery na potomky doprava for j = x.n; j >= i+1; j = j - 1 x.children[j + 1] = x.children[j] // 2.3 zapojime z x.children[i+1] = z // 2.4 vlozime k_t do x x.keys[i] = y.keys[t-1] x.n = x.n + 1
proc tree-insert(T, k, d) r = T.root if r.n == 2 * t - 1 // koren je zaplneny s = new_node() T.root = s s.leaf = false s.n = 0 s.children[0] = r; split-child(s,0) // toto rozdeli puvodni koren tree-insert-nonfull(s, k, d) else tree-insert-nonfull(r, k, d)
proc tree-insert-nonfull(x, k, d) i = x.n - 1 // 1. x je list, uz provadime pridani if x.leaf // 1.1 vsechny klice vetsi nez k posuneme doprava while i >= 0 and k < x.keys[i] x.keys[i+1] = x.keys[i] x.data[i+1] = x.data[i] i = i - 1 // 1.2 vlozime k a d x.keys[i+1] = k x.data[i+1] = d x.n = x.n + 1// 2. x neni list, musime najit potomka, kterym budeme pokracovat else // 2.1 najdeme spravneho potomka while i >= 0 and k < x.keys[i] i = i - 1 i = i + 1 // 2.2 kdyz je potomek zaplnen, rozdelime ho if x.children[i].n == 2 * t - 1 split-child(x, i) // overime, do ktereho ze vzniklych podstromu patri k if k > x.keys[i] i = i + 1 // 2.3 provedeme pridani do potomka (není zaplněn) tree-insert-nonfull(x.children[i], k, d)
Vkládání
Mazání prvku (dvoufázové) O(tlogtn)
1. fáze - vlastní smazání:
Operací tree-search nalezneme uzel x a index i, tak, že k == x.keys[i]
Pokud je x list, provedeme smazání tak, že jej odstraníme z x.keys (posunutí všech prvků na indexech vyšší než i o jedna doleva). Podobně upravíme i položky x.data a x.n snížíme o 1. Uzel x pošleme do druhé fáze.)
Pokud je x interní uzel, nahradíme x.keys[i], který je určitě neprázný. Největší klíč v tomto stromu je pořádkovým předchůdcem klíče k. Klíč m se původně nacházel v listu, ze kterého ho odstraníme tak, jako v bodě 2 (včetně toho, že list pošleme do druhé fáze).
2. fáze - úprava počtu klíčů v uzlech:
Je-li x kořen, nebo je-li x.n >= t-1, algoritmus končí
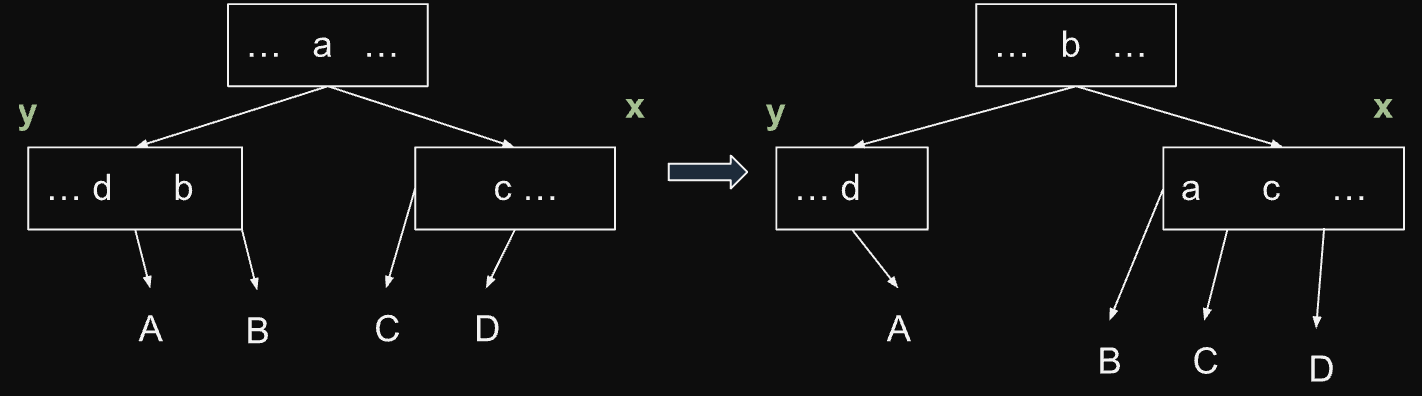
Má-li x sourozence y a y.n > t-1, pak provedeme přelití jednoho klíče (a jeho satelitních dat) mezi x,y a jejich rodičem. Obrázek ukazuje situaci, kdy je y levým sourozencem x, opačná situace je symetrická. Po přelití algoritmus končí.
Oba sourozenci x mají t-1 prvků. Vybereme si jednoho souseda y a spojíme ho s uzlem x a jedním klíčem z rodiče do nového uzlu s 2 * t - 1 klíči. Na následujícím obrázku je y pravým sourozencem x (opačná situace je symetrická). Po spojení uzlů pokračujeme novou iterací fáze 2, do které pošleme rodiče uzlu x. Z rodiče jsme totiž odebrali jeden klíč a jeho počet klíčů se tak mohl dostat pod t - 1